樣本的已知函數;其作用是把樣本中有關總體的資訊彙集起來;是數理統計學中一個重要的基本概念。統計量依賴且隻依賴於樣本x1,x2,…xn;它不含總體分佈的任何未知參數。從樣本推斷總體(見統計推斷)通常是通過統計量進行的。例如x1,x2,…,xn是從正態總體N(μ,1)(見正態分佈)中抽出的簡單隨機樣本,其中均值(見數學期望)μ是未知的,為瞭對μ作出推斷,計算樣本均值
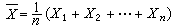 。可以證明,在一定意義下,
X包含樣本中有關
μ的全部信息,因而能對
μ作出良好的推斷。這裡
X隻依賴於樣本
x
1,
x
2,…,
x
n,是一個統計量。
。可以證明,在一定意義下,
X包含樣本中有關
μ的全部信息,因而能對
μ作出良好的推斷。這裡
X隻依賴於樣本
x
1,
x
2,…,
x
n,是一個統計量。
常用統計量 有下面幾種。
樣本矩 設x1,x2,…,xn是一個大小為n的樣本,對自然數k,分別稱
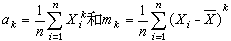 為
k階樣本原點矩和
k階樣本中心矩,統稱為樣本矩。許多最常用的統計量,都可由樣本矩構造。例如,樣本均值
為
k階樣本原點矩和
k階樣本中心矩,統稱為樣本矩。許多最常用的統計量,都可由樣本矩構造。例如,樣本均值
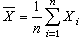 (即
α
1)和樣本方差
(即
α
1)和樣本方差
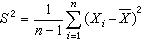
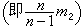 是常用的兩個統計量,前者反映總體中心位置的信息,後者反映總體分散情況。還有其他常用的統計量,如樣本標準差
是常用的兩個統計量,前者反映總體中心位置的信息,後者反映總體分散情況。還有其他常用的統計量,如樣本標準差
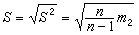 ,樣本變異系數
S/
X,樣本偏度
,樣本變異系數
S/
X,樣本偏度
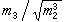 ,樣本峰度
,樣本峰度
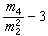 等都是樣本矩的函數。若(
x
1,
Y
1),(
x
2,
Y
2),…,(
x
n,
Y
n)是從二維總體(
x,
Y)抽出的簡單樣本,則樣本協方差
等都是樣本矩的函數。若(
x
1,
Y
1),(
x
2,
Y
2),…,(
x
n,
Y
n)是從二維總體(
x,
Y)抽出的簡單樣本,則樣本協方差
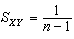 ·
·
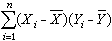 及樣本相關系數
及樣本相關系數
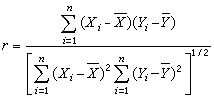 也是常用的統計量,
r可用於推斷
x和
Y的相關性。
也是常用的統計量,
r可用於推斷
x和
Y的相關性。
次序統計量 把樣本X1,x2,…,xn由小到大排列,得到
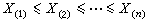 ,稱之為樣本
x
1,
x
2,…,
x
n的次序統計量。其中最小次序統計量
x
(1)最大次序統計量
x
(n)稱為極值,在那些如年枯水量、年最大地震級數、材料的斷裂強度等的統計問題中很有用。還有一些由次序統計量派生出來的有用的統計量,如:樣本中位數
,稱之為樣本
x
1,
x
2,…,
x
n的次序統計量。其中最小次序統計量
x
(1)最大次序統計量
x
(n)稱為極值,在那些如年枯水量、年最大地震級數、材料的斷裂強度等的統計問題中很有用。還有一些由次序統計量派生出來的有用的統計量,如:樣本中位數
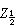 是總體分佈中心位置的一種度量,若樣本大小
n為奇數,
是總體分佈中心位置的一種度量,若樣本大小
n為奇數,
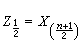 ,若
n為偶數,
,若
n為偶數,
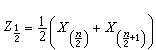 ,它容易計算且有良好的穩健性。樣本
p分位數Z
p(0<
p<1)及極差
x
(n)-
x
(1)也是重要的統計量。其中
Z
p當
,它容易計算且有良好的穩健性。樣本
p分位數Z
p(0<
p<1)及極差
x
(n)-
x
(1)也是重要的統計量。其中
Z
p當
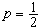 時即為中位數,而當
時即為中位數,而當
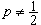 時,
時,
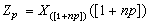 表示不超過1+
n
p的最大整數)。樣本分位數的一個重要應用是構造連續總體分佈的非參數性容忍區間(見
區間估計)。
表示不超過1+
n
p的最大整數)。樣本分位數的一個重要應用是構造連續總體分佈的非參數性容忍區間(見
區間估計)。
U統計量 這是W.霍夫丁於1948年引進的,它在非參數統計中有廣泛的應用。其定義是:設x1,x2,…,xn,為簡單樣本,m為不超過n的自然數,
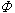 為
m元對稱函數,則稱
為
m元對稱函數,則稱
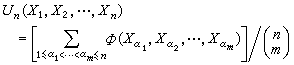 為樣本
x
1,
x
2,…,
x
n的以
為核的
U統計量。樣本均值和樣本方差都是它的特例。從霍夫丁開始,這種統計量的大樣本性質得到瞭深入的研究,主要應用於構造非參數性的量的一致最小方差無偏估計(見
點估計),並在這種估計的基礎上檢驗非參數性總體中的有關假設。
為樣本
x
1,
x
2,…,
x
n的以
為核的
U統計量。樣本均值和樣本方差都是它的特例。從霍夫丁開始,這種統計量的大樣本性質得到瞭深入的研究,主要應用於構造非參數性的量的一致最小方差無偏估計(見
點估計),並在這種估計的基礎上檢驗非參數性總體中的有關假設。
秩統計量 把樣本X1,X2,…,Xn按大小排列為
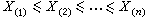 ,若
,若
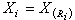 則稱
R
i為
x
i的秩,全部
n個秩
R
1,
R
2,…,
R
n構成秩統計量,它的取值總是1,2,…,
n的某個排列。秩統計量是非參數統計的一個主要工具。
則稱
R
i為
x
i的秩,全部
n個秩
R
1,
R
2,…,
R
n構成秩統計量,它的取值總是1,2,…,
n的某個排列。秩統計量是非參數統計的一個主要工具。
還有一些統計量是因其與一定的統計方法的聯系而引進的。如假設檢驗中的似然比原則所導致的似然比統計量,K.皮爾森的擬合優度(見假設檢驗)準則所導致的ⅹ2統計量,線性統計模型中的最小二乘法所導致的一系列線性與二次型統計量,等等。
充分性與完全性 統計量是由樣本加工而成的,在用統計量代替樣本作統計推斷時,樣本中所含的信息可能有所損失,如果在將樣本加工為統計量時,信息毫無損失,則稱此統計量為充分統計量。例如,從一大批產品中依次抽出n個,若第i次抽出的是合格品,則xi=0,否則xi=1(i=1,2,…,n)。總體分佈取決於整批產品的廢品率p,可以證明:統計量
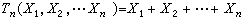 ,即樣本中的廢品個數,包含瞭(
x
1,
x
2,…,
x
n)中有關
p的全部信息,是一個充分統計量。若取
m<
n,令
T
m(
x
1,
,即樣本中的廢品個數,包含瞭(
x
1,
x
2,…,
x
n)中有關
p的全部信息,是一個充分統計量。若取
m<
n,令
T
m(
x
1,
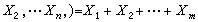 ,則
T
m仍是一個統計量,不過不是充分的。
,則
T
m仍是一個統計量,不過不是充分的。
充分性是數理統計的一個重要基本概念,它是R.A.費希爾在1925年引進的,費希爾提出,並由J.奈曼和P.R.哈爾莫斯在1949年嚴格證明瞭一個判定統計量充分性的方法,叫因子分解定理。這個定理適用面廣且應用方便,利用它可以驗證很多常見統計量的充分性。例如,若正態總體有已知方差,則樣本均值x是充分統計量。若正態總體的均值、方差都未知,則樣本均值和樣本方差S2合起來構成充分統計量(x,S2)。一個統計量是否充分,與總體分佈有密切關系。
將樣本加工成統計量要求越簡單越好。簡單的程度的大小,主要用統計量的維數來衡量。簡單地講,若統計量T2是由統計量T1加工而來(即T2是T1的函數),則T2比T1簡單。在此意義上,最簡單的充分統計量叫極小充分統計量。這是E.L.萊曼和H.謝菲於1950年提出的。前例中的充分統計量都有極小性。在任何情況下,樣本x1,x2,…,xn本身就是一個充分統計量,但一般不是極小的。
關於統計量的另一個重要的基本概念是完全性。設T為一統計量,θ為總體分佈參數,若對θ的任意函數g(θ),基於T的無偏估計至多隻有一個(以概率1相等的兩個估計量視為相同),則稱T為完全的。
抽樣分佈 統計量的分佈叫抽樣分佈。它與樣本分佈不同,後者是指樣本x1,x2,…,xn的聯合分佈。
統計量的性質以及使用某一統計量作推斷的優良性,取決於其分佈。所以抽樣分佈的研究是數理統計中的重要課題。尋找統計量的精確的抽樣分佈,屬於所謂的小樣本理論(見大樣本統計)的范圍,但是隻在總體分佈為正態時取得比較系統的結果。對一維正態總體,有三個重要的抽樣分佈,即ⅹ2分佈、t分佈和F分佈。
ⅹ2分佈 設隨機變量x1,x2,…,xn是相互獨立且服從標準正態分佈N(0,1),則隨機變量
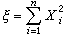 的分佈稱為自由度為
n的ⅹ
2分佈(其密度函數及下文的
t分佈、
F分佈的密度函數表達式均見
概率分佈)。這個分佈是 F.赫爾梅特於1875年在研究正態總體的樣本方差時得到的。若
x
1,
x
2,…,
x
n是抽自正態總體
N(
μ,
σ
2)的簡單樣本,則變量
的分佈稱為自由度為
n的ⅹ
2分佈(其密度函數及下文的
t分佈、
F分佈的密度函數表達式均見
概率分佈)。這個分佈是 F.赫爾梅特於1875年在研究正態總體的樣本方差時得到的。若
x
1,
x
2,…,
x
n是抽自正態總體
N(
μ,
σ
2)的簡單樣本,則變量
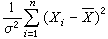 服從自由度為
n-1的ⅹ
2分佈。若
x
1,
x
2,…,
x
n服從的不是標準正態分佈,而依次是正態分佈
N(
μ
i,1)(
i=1,2,…,
n),則
服從自由度為
n-1的ⅹ
2分佈。若
x
1,
x
2,…,
x
n服從的不是標準正態分佈,而依次是正態分佈
N(
μ
i,1)(
i=1,2,…,
n),則
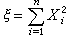 的分佈稱為非中心ⅹ
2分佈,
的分佈稱為非中心ⅹ
2分佈,
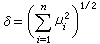 稱為非中心參數。當
δ=0時即前面所定義的ⅹ
2分佈。為此,有時也稱它為中心ⅹ
2分佈。中心與非中心的ⅹ
2分佈在正態線性模型誤差方差的估計理論中,在正態總體方差的檢驗問題中(見
假設檢驗),以及一般地在正態變量的二次型理論中都有重要的應用。
稱為非中心參數。當
δ=0時即前面所定義的ⅹ
2分佈。為此,有時也稱它為中心ⅹ
2分佈。中心與非中心的ⅹ
2分佈在正態線性模型誤差方差的估計理論中,在正態總體方差的檢驗問題中(見
假設檢驗),以及一般地在正態變量的二次型理論中都有重要的應用。
t分佈 設隨機變量ξ,η獨立,且分別服從正態分佈N(δ,1)及自由度n的中心ⅹ2分佈,則變量
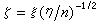 的分佈稱為自由度
n、非中心參數
δ的非中心
t分佈;當
δ=0時稱為中心
t分佈。若
x
1,
x
2,…,
x
n是從正態總體
N(
μ,
σ
2)中抽出的簡單樣本,以
x記樣本均值,以
的分佈稱為自由度
n、非中心參數
δ的非中心
t分佈;當
δ=0時稱為中心
t分佈。若
x
1,
x
2,…,
x
n是從正態總體
N(
μ,
σ
2)中抽出的簡單樣本,以
x記樣本均值,以
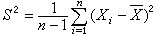 記樣本方差,則
記樣本方差,則
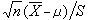 服從自由度
n-1的
t分佈。這個結果是英國統計學傢W.S.戈塞特(又譯哥色特,筆名“學生”)於1908年提出的。
t分佈在有關正態總體均值的估計和檢驗問題中,在正態線性統計模型對可估函數的推斷問題中有重要意義,
t分佈的出現開始瞭數理統計的小樣本理論的發展。
服從自由度
n-1的
t分佈。這個結果是英國統計學傢W.S.戈塞特(又譯哥色特,筆名“學生”)於1908年提出的。
t分佈在有關正態總體均值的估計和檢驗問題中,在正態線性統計模型對可估函數的推斷問題中有重要意義,
t分佈的出現開始瞭數理統計的小樣本理論的發展。
F分佈 是 R.A.費希爾在20世紀20年代提出的。設隨機變量ξ,η獨立,ξ服從自由度m、非中心參數δ的非中心ⅹ2分佈,η服從自由度n的中心ⅹ2分佈,則
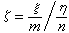 的分佈稱為自由度(
m,
n)、非中心參數
δ的非中心
F分佈,當
δ=0時稱為中心
F分佈。若
x
1,
x
2,…,
x
m和
Y
1,
Y
2,…,
Y
n分別是從正態總體
N(
μ,
σ
2)和
N(
v,
σ
2),中抽出的獨立簡單樣本,以
S
1
2和
S
2
2分別記為諸
x
i和諸
Y
i的樣本方差,則方差比統計量
S
1
2/
S
2
2服從自由度(
m-1,
n-1)的中心
F分佈。中心和非中心的
F分佈在
方差分析理論中有重要應用。
的分佈稱為自由度(
m,
n)、非中心參數
δ的非中心
F分佈,當
δ=0時稱為中心
F分佈。若
x
1,
x
2,…,
x
m和
Y
1,
Y
2,…,
Y
n分別是從正態總體
N(
μ,
σ
2)和
N(
v,
σ
2),中抽出的獨立簡單樣本,以
S
1
2和
S
2
2分別記為諸
x
i和諸
Y
i的樣本方差,則方差比統計量
S
1
2/
S
2
2服從自由度(
m-1,
n-1)的中心
F分佈。中心和非中心的
F分佈在
方差分析理論中有重要應用。
多維正態總體的重要的抽樣分佈有維夏特分佈和霍特林的T2分佈(見多元統計分析)。
一個統計量若服從某分佈,常以該分佈的名字命名該統計量,如ⅹ2統計量、F統計量、T2統計量等。
由於尋找精確的抽樣分佈有困難,統計學者轉而研究當樣本大小n→∞時統計量的漸近分佈(即極限分佈),這種研究是數理統計大樣本理論的基礎性工作。已經有很多重要的統計方法,就是基於這種工作而提出的。像K.皮爾森關於擬合優度統計量的極限分佈是ⅹ2分佈的著名結果(1900)就是一個有代表性的例子。
參考書目
復旦大學編:《概率論》(第2冊,數理統計),人民教育出版社,北京,1979。
費史著,王福保譯:《概率論及數理統計》,上海科學技術出版社,上海,1962。(M.Fisz,Wahrscheinlichkei-tsrechnung und MatheMatische Statistik,VEB Deu-tscher Verlag der Wissenschaften,Berlin,1958.)
陳希孺著:《數理統計引論》,科學出版社,北京,1981。