多個變數統計分析技術在社會研究中的運用。又稱多元分析。它的分類方法很多,主要有按變數層次分類和按功能分類。
表1 變數層次分類表
社會現象是複雜的,例如一種現象往往不止是一種原因引起的;或一種種社會現象往往同時扮演因和果的角色;或作為因的各種現象之間又存在著某種聯系;或在確認現象間的相關或因果聯系時,往往還需要通過引入其他變量,才可加以確認。因此,多變量分析除根據變量層次分類外,還可根據多變量分析的目的、功能或用途來分類,便於使用者根據需要選擇不同的分析技術。在選擇時,要註意變量的層次。
詳析模式 為瞭深入研究和分析兩個變量x和y之間的關系,需要引進第3個變量z,然後通過3個變量的因果模型分析,詳細分析所要研究的兩個變量x和y之間的關系。其中包括辨明變量x和y之間是否確有關系,關系的方向如何,以及辨明變量 z與變量x和y之間的關系類型,是否存在中介的變量等等。例如,根據統計,婚齡長的人,患病率高些。初看起來,似乎變量婚齡與變量患病率之間存在著正相關。但如果引入變量年齡z,則發現這樣一個事實:年齡大,同時也是婚齡長和患病率高的原因。實際婚齡和患病率之間並非存在真正因果的關系。可見,為瞭探討婚齡和患病率之間是否確有關系,必須引入年齡z方能得出正確結論。又如,增加教育經費和提高教育質量之間存在著正相關。但教育經費 x不能直接轉化為教育質量y,其間必然還要通過中間措施,如購置教學設備z。所以,購置教學設備成為教學經費和教育質量形成正相關必不可少的一個中介變量。
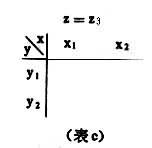
引入變量 z對原有變量x和y關系進行分析,是通過對變量z的控制進行的,因此變量z又稱控制變量。具體作法是,對於定類或定序變量采用“分表法”,對原有變量x和y作交叉分類表,又稱原表(表2),按控制變量z的不同取值:z=z1,z=z2,z=z3,……再作成分表(表a,表b,表c)。然後比較原表和分表中變量x和y的相關系數。對於定類變量,可通過λ系數或τ系數的比較;對於定序變量,可通過 γ系數的比較;對於定距變量,可采用偏相關系數法…,即直接比較相關系數
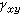 和偏相關系數
和偏相關系數
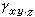 ,無須再作原表和分表。這兩種方法的原理是一樣的。
,無須再作原表和分表。這兩種方法的原理是一樣的。
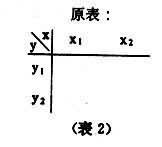 表a
表a
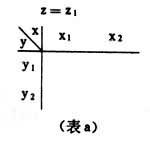 表b
表b
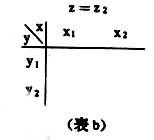 表c
表c
為瞭對詳析模式有一清晰瞭解,必須搞清控制變量z在變量x和y中所處的位置。如果控制變量z位於變量x和y之前(圖1)則稱z為前置變量;如果控制變量z位於變量x和y之間(圖2)則稱z為中介變量。
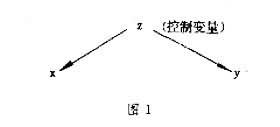 圖1
圖1
 圖2
圖2
根據變量z控制前後,變量x和y相關程度的變化,可對變量x和y之間的關系作如下幾種解釋。
①原表和各分表中,變量x和y的相關程度都不變,則可確信變量x和y之間的原關系是成立的,是存在相關的,且其相關程度和原表是一樣的。
②若分表中,變量x和y的相關程度和原表相比,呈現復雜的情況:有的不變或增加;有的減少或消失。這時可將變量 z看作是討論變量x和y之間關系的一種分類或條件,z又稱條件變量。
③若 z控制後,所有分表中變量x和y的關系都消失瞭,則說明變量 z可能是變量x和y變化的共因,即前置變量(圖1),但也可能是中介變量(圖2)。對於前者(圖1),嚴格說來變量x和y並不存在因果聯系,因此變量 x和y之間的相關稱偽相關或虛假相關。即用變量z就可解釋變量x和y之間的關系。例如,前述變量年齡z就可能是變量婚齡x和變量患病率y產生虛假相關的前置變量。而購置教學設備必然發生在增加教學經費之後和提高教育質量之前,它稱作中介變量。有瞭中介變量,對變量x和y之間的關系就可作進一步的分析或解釋。所謂變量x和y關系的消失,並不意味著相關系數的計算結果正好為零。對於抽樣來說,變量間相關為零的原假設被接受就可看作是關系的消失。若變量z控制後,分表中所有變量x和y的關系仍然是顯著的,但都減弱瞭,則說明變量x和y的關系中部分是由於z的存在。
④對於圖1的因果模型,詳析模式不僅可以討論變量x和y之間原有關系不為零的情況:
≠0,也可討論原有關系為零的情況:
=0。因為偏相關系數
和原有相關系數
存在以下關系式:
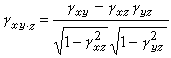
當
=0,
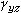 ≠0,
≠0,
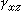 ≠0,且
和
異號時,則
>0。它表示變量
x和
y之間的關系,隻有當變量
z得以控制後方被釋放出來。所以美國學者M.羅森伯格稱
z為壓抑變量,而原有相關
=0是虛假的,或稱虛假的零相關。羅森伯格還設想瞭
和
可能反向的情況。它表示原有相關系數的極性(正向或反向),實際是歪曲瞭事實的真相,隻有當變量
z得以控制後,變量
x和
y之間相關的真實極性才得以顯示,這種情況下的控制變量
z稱作歪曲變量。
≠0,且
和
異號時,則
>0。它表示變量
x和
y之間的關系,隻有當變量
z得以控制後方被釋放出來。所以美國學者M.羅森伯格稱
z為壓抑變量,而原有相關
=0是虛假的,或稱虛假的零相關。羅森伯格還設想瞭
和
可能反向的情況。它表示原有相關系數的極性(正向或反向),實際是歪曲瞭事實的真相,隻有當變量
z得以控制後,變量
x和
y之間相關的真實極性才得以顯示,這種情況下的控制變量
z稱作歪曲變量。
多因分析 研究社會現象的產生是若幹原因共同作用的模型(圖3):y=α11x1+α12x2+……α1nxn多因分析除瞭多元回歸外,還可將回歸與相關技術結合起來,稱作典型相關分析技術。例如采用回歸技術,用一組變量測定人們的社會經濟地位,用另一組變量測定人們的現代化觀念,就可采用典型相關分析來分析社會經濟地位和現代化觀念之間的關系(見回歸分析)。
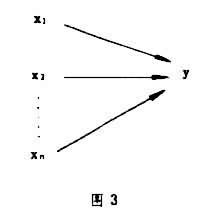 圖3
圖3
多因分析中的因變量又可能同時是另一變量的自變量,從而形成多級的因果鏈(圖4),這時可采用路徑分析技術。
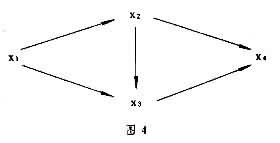 圖4
圖4
多變量的綜合與提取 當多個變量間存在一定的相關性時,可利用聚類分析、因素分析、主成分分析法對信息進行綜合、提取與歸類(見因子分析)。
多變量分析在社會研究中的應用正逐步得到推廣。但各種統計技術的運用,無不取決於模型的選擇,而模型的選擇是帶有主觀性的,研究者必須對研究對象作深入的定性研究,以便主觀上作出符合客觀實際的模型選擇。